Working Environment and what is new in this version
-- coding: utf-8 --
Jupyter Notebook with Python 3
Created on Sat Feb 22, 2018
Find out the data-related jobs in Ontario from Indeed.ca
Version 2 : wanna check more information of ‘Job Requiretments’ and select more features details from linked pages
Data visualization using matplotlib, seaborn and tableau v10.5
Try to analysis key words from job responsibility using NLTK package with brown / pos tag categories
@author: Haby
Job Post Part
Demo Code and Functions
import pip
def install(package):
pip.main(['install', package])
# install Natural language toolkit
install('nltk')
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
Requirement already satisfied: nltk in e:\software\anaconda\lib\site-packages
Requirement already satisfied: six in e:\software\anaconda\lib\site-packages (from nltk)
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\adien\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
[nltk_data] Downloading package stopwords to
[nltk_data] C:\Users\adien\AppData\Roaming\nltk_data...
[nltk_data] Package stopwords is already up-to-date!
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] C:\Users\adien\AppData\Roaming\nltk_data...
[nltk_data] Unzipping taggers\averaged_perceptron_tagger.zip.
True
# import package
import requests
import bs4
from bs4 import BeautifulSoup
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import nltk
# Demo Code and Function
# url
url ='https://ca.indeed.com/jobs?q=data&l=Ontario'
# get the url
page = requests.get(url)
#decode with BeautifulSoup
soup = BeautifulSoup(page.text, 'html.parser')
# job title is under div/a node with data-tn-element/title label
def job_title(soup):
jobs = []
for div in soup.find_all(name='div', attrs={'class':'row'}):
for a in div.find_all(name='a', attrs={'data-tn-element':'jobTitle'}):
jobs.append(a['title'])
return(jobs)
# This company code is from : https://medium.com/@msalmon00/web-scraping-job-postings-from-indeed-96bd588dcb4b
# company title : <span class="company"> in div node
def company(soup):
companies = []
for div in soup.find_all(name='div', attrs={'class':'row'}):
company = div.find_all(name='span', attrs={'class':'company'})
# if can be select by company
if len(company) > 0:
for b in company:
companies.append(b.text.strip())
# else pick up by result-link-source
else:
sec_try = div.find_all(name='span', attrs={'class':'result-link-source'})
for span in sec_try:
companies.append(span.text.strip())
return(companies)
# location
def location(soup):
locations = []
spans = soup.find_all('span', attrs={'class':'location'})
for span in spans:
locations.append(span.text)
return(locations)
# Salary : most of salary doens't exist, fill NA
def salary(soup):
salaries = []
for div in soup.find_all(name='div', attrs={'class':'row'}):
try:
salaries.append(div.find(name = 'span',attrs = {'class','no-wrap'}).text.strip())
except:
salaries.append('Nothing_found')
return(salaries)
# Post Day
def post_day(soup):
postday = []
for div in soup.find_all(name = 'div',attrs = {'class','result-link-bar'}):
try :
postday.append(div.find('span',attrs={'class': 'date'}).text)
#spans = soup.findAll('span', attrs={'class': 'date'})
except :
postday.append('New Post')
return(postday)
# reviews
def review(soup):
review = []
for div in soup.find_all(name='div', attrs={'class':'row'}):
try:
review.append(div.find(name = 'span',attrs = {'class','slNoUnderline'}).text.strip())
except:
review.append('0 reviews')
return(review)
# post functions : what we get is the absolute address, so we need to add 'ca.indeed.com'
def post_link(soup):
link = []
for div in soup.find_all(name='div', attrs={'class':'row'}):
for a in div.find_all(name='a', attrs={'data-tn-element':'jobTitle'}):
link.append('http://ca.indeed.com'+a['href'])
return(link)
# concat all
columns = {'job_title' : job_title(soup), 'company_name' : company(soup),
'location' : location(soup), 'salary' : salary(soup),
'review': review(soup), 'post day' : post_day(soup),
'links': post_link(soup)
}
sample_df = pd.DataFrame(columns)
print(sample_df)
company_name \
0 LG Electronics
1 IFDS Group
2 Interactyx
3 Sun Life Financial
4 Loblaw
5 CHEO
6 Validus Research Inc.
7 University of Western Ontario
8 M.W.N. Technologies Inc.
9 ServiceSimple
10 Global Pharmatek
11 BlueDot
12 Quandl Inc
13 Sobeys
14 Accenture
15 Excis Ltd (www.excis.com)
job_title \
0 AI / Machine Learning Scientist – Toronto AI Lab
1 Data Center
2 Business Intelligence Developer
3 Data Analyst, Client Analytics
4 Sr. Manager, Data, Reporting & Analytics
5 Oncology Data Administrator, MDU
6 Research Analyst – Junior Statistician
7 Research Scientist
8 Entry-level Data Scientist
9 Data Analyst and Marketing Intern
10 Data Power Admin
11 Data Scientist
12 Junior Data Engineer (ETL)
13 Data Visualization Analyst - Tableau
14 Test Data Manager (TDM)
15 Data Center Engineer
links location \
0 http://ca.indeed.com/pagead/clk?mo=r&ad=-6NYlb... Toronto, ON
1 http://ca.indeed.com/pagead/clk?mo=r&ad=-6NYlb... Toronto, ON
2 http://ca.indeed.com/pagead/clk?mo=r&ad=-6NYlb... Ottawa, ON
3 http://ca.indeed.com/pagead/clk?mo=r&ad=-6NYlb... Toronto, ON
4 http://ca.indeed.com/rc/clk?jk=40544eff6430811... Brampton, ON
5 http://ca.indeed.com/rc/clk?jk=b34dcb56d215e1e... Ontario
6 http://ca.indeed.com/company/Validus-Research-... Waterloo, ON
7 http://ca.indeed.com/rc/clk?jk=5d92f59123260f1... London, ON
8 http://ca.indeed.com/company/M.W.N.-Technologi... Mississauga, ON
9 http://ca.indeed.com/company/Service-Simple/jo... Toronto, ON
10 http://ca.indeed.com/rc/clk?jk=1971e7726426442... Ontario
11 http://ca.indeed.com/rc/clk?jk=0d86897c7f75d89... Toronto, ON
12 http://ca.indeed.com/rc/clk?jk=b37b64344c41202... Toronto, ON
13 http://ca.indeed.com/rc/clk?jk=07d233c4fb41d4e... Mississauga, ON
14 http://ca.indeed.com/pagead/clk?mo=r&ad=-6NYlb... Toronto, ON
15 http://ca.indeed.com/pagead/clk?mo=r&ad=-6NYlb... Toronto, ON
post day review salary
0 New Post 1,531 reviews Nothing_found
1 2 days ago 6 reviews Nothing_found
2 New Post 0 reviews Nothing_found
3 New Post 781 reviews Nothing_found
4 1 day ago 1,646 reviews Nothing_found
5 2 days ago 7 reviews $23.92 - $29.36 an hour
6 17 days ago 0 reviews Nothing_found
7 3 days ago 100 reviews Nothing_found
8 2 days ago 0 reviews Nothing_found
9 30+ days ago 0 reviews Nothing_found
10 30+ days ago 0 reviews Nothing_found
11 5 days ago 0 reviews Nothing_found
12 18 days ago 0 reviews Nothing_found
13 4 days ago 1,596 reviews Nothing_found
14 New Post 12,530 reviews Nothing_found
15 New Post 0 reviews Nothing_found
# pickup usful information from linked pages
# info
words = []
def info(link) :
soup = BeautifulSoup(requests.get(link).text,'html.parser')
words.extend(soup.find('span',attrs={'id': 'job_summary'}).text.split())
return(words)
# demo
info('https://ca.indeed.com/viewjob?jk=53d052c5a4791a68&tk=1c77cg3ku41dk895&from=serp&alid=3&advn=6591858045400699')[:10]
# There are lots of meanless words, try to drop them by stop words list
['At',
'Sun',
'Life,',
'we',
'work',
'together,',
'share',
'common',
'values',
'and']
Iterating 50 Pages
# url
url ='https://ca.indeed.com/jobs?q=data&l=Ontario&start='
# loop pages
page = [i*10 for i in range(0,51)]
# new dataframe for data
df = pd.DataFrame()#columns = columns)
# loop 50 pages
for i in page :
url = url + str(i)
# get the url
page = requests.get(url)
#specifying a desired format of “page” using the html parser - this allows python to read the various components of the page, rather than treating it as one long string.
soup = BeautifulSoup(page.text, 'html.parser')
# concat all
temp = pd.DataFrame([job_title(soup),company(soup),location(soup),
salary(soup),review(soup),post_day(soup),post_link(soup)])
df = df.append(temp.T,ignore_index = True)
df.columns = ['job_title', 'company_name', 'location', 'salary', 'review',
'post day','links']
print(df.head())
print('-'*80)
print('Total Data we have now: ',len(df))
job_title company_name \
0 AI / Machine Learning Scientist – Toronto AI Lab LG Electronics
1 Data Center IFDS Group
2 Data Analyst, Client Analytics Sun Life Financial
3 Data Scientist Capital One
4 Sr. Manager, Data, Reporting & Analytics Loblaw
location salary review post day \
0 Toronto, ON Nothing_found 1,531 reviews New Post
1 Toronto, ON Nothing_found 6 reviews 2 days ago
2 Toronto, ON Nothing_found 781 reviews New Post
3 Toronto, ON Nothing_found 5,321 reviews New Post
4 Brampton, ON Nothing_found 1,646 reviews 1 day ago
links
0 http://ca.indeed.com/pagead/clk?mo=r&ad=-6NYlb...
1 http://ca.indeed.com/pagead/clk?mo=r&ad=-6NYlb...
2 http://ca.indeed.com/pagead/clk?mo=r&ad=-6NYlb...
3 http://ca.indeed.com/pagead/clk?mo=r&ad=-6NYlb...
4 http://ca.indeed.com/rc/clk?jk=40544eff6430811...
--------------------------------------------------------------------------------
Total Data we have now: 815
Data Cleaning
# Job title
# job title : split first title outside by '-' , ',','?','$'
df['First_title'] = df['job_title'].map(lambda x : x.split('–')[0].split(',')[0].split('(')[0].split('$')[0].split('-')[0].strip())
# top 15 job titles
df['First_title'].value_counts()[:15].plot.barh(title = 'Top 15 Most Wanted Job Titles \n Ordered Ascendingly',
colormap = 'summer')
plt.show()

# salary
# most of salary are 'Nothing_found', replace by 0
df['salary'] = df['salary'].replace('Nothing_found','0')
# make all salary / year
# since most salary exists is a range, get mean value of salary
mean_salary = []
for s in df['salary'] :
if s != '0' :
min_sal = float(s.split()[0].replace('$','').replace(',',''))
if s.split()[1] != '-' :
mean_sal = min_sal
#print(mean_sal)
unit = s.split()[-1]
# print(mean_sal,unit)
if unit == 'week' :
# assume 52 weeks / year
mean_salary.append(mean_sal * 52)
elif unit == 'month' :
mean_salary.append(mean_sal * 12)
elif unit == 'hour':
# assume 40 hours/ week
mean_salary.append(mean_sal * 40*52)
else :
mean_salary.append(mean_sal)
else :
max_sal = float(s.split()[2].replace('$','').replace(',',''))
mean_sal = (min_sal+max_sal)/2
#print(mean_sal)
unit = s.split()[-1]
# print(mean_sal,type(mean_sal),unit)
if unit == 'week' :
# assume 52 weeks / year
mean_salary.append(mean_sal * 52)
#print(df['mean_sal'],'in df')
elif unit == 'month' :
mean_salary.append(mean_sal * 12)
elif unit == 'hour':
# assume 40 hours/ week
mean_salary.append(mean_sal * 40*52)
else :
mean_salary.append(mean_sal)
else :
mean_salary.append(0)
len(mean_salary)
df['mean_sal'] = mean_salary
# number of reviews
df['review number'] = df['review'].map(lambda x : int(x.split()[0].replace(',','')))
python Visualization
#Visualization
# salary visualization
g = sns.kdeplot(df['mean_sal'],shade = True,color = 'g')
g.set_title('Mean Salary for data-related jobs')
plt.show()
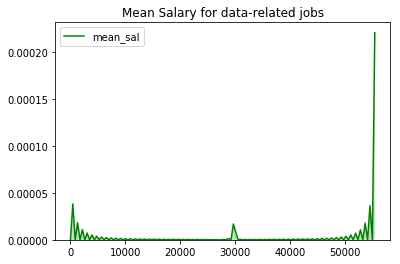
df['mean_sal'].value_counts()
0.0 757
55411.2 46
30000.0 4
29640.0 4
55169.0 4
Name: mean_sal, dtype: int64
Salary is different with last version since many posts are renewed now and more posts won’t offer salary info in posts.
# company name
# graph the top 20 companies who needed the data-related employees recently
df['company_name'].value_counts()[:20].plot.barh(title = 'Top 20 Companies Who Need Data-related Employees by Feb/25/2018',
colormap = 'summer')
plt.show()

# reviews visualization
# plot top 10 companies with most reviews
df[['review number','company_name']].groupby('company_name').mean().sort_values(by = ['review number'],
ascending = False).head(10).plot.barh(title = 'Top 10 companies with most reviews \n Who Need Employees Recently',
colormap = 'summer')
plt.show()
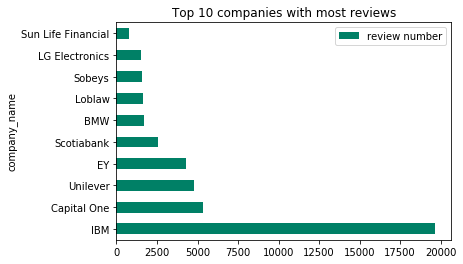
Amazon disappeared this time, I’m thinking like they won’t need more employees recently, so there are no info they posts
# Do more work on link column, check more details key features
import time
for l in df['links'] :
# get all words for linked pages by function info
info(l)
# stop 0.5s for each loop
time.sleep(0.5)
print('Total words now: ',len(words))
print('-'*40)
print('Unique words now: ',len(set(words)))
Total words now: 408426
----------------------------------------
Unique words now: 5012
# stop words
stopwords = nltk.corpus.stopwords.words('english')
# drop words exist in stopwords
keywords = []
for word in words :
if word.lower() not in stopwords :
# drop the words whose length is less than 3
if len(word) >= 3 :
keywords.append(word.lower())
print('Total keywords now: ',len(keywords))
print('-'*40)
print('Unique Keywords now: ',len(set(keywords)))
Total keywords now: 266685
----------------------------------------
Unique Keywords now: 4237
# Pos tag words
word_tag = nltk.pos_tag(keywords)
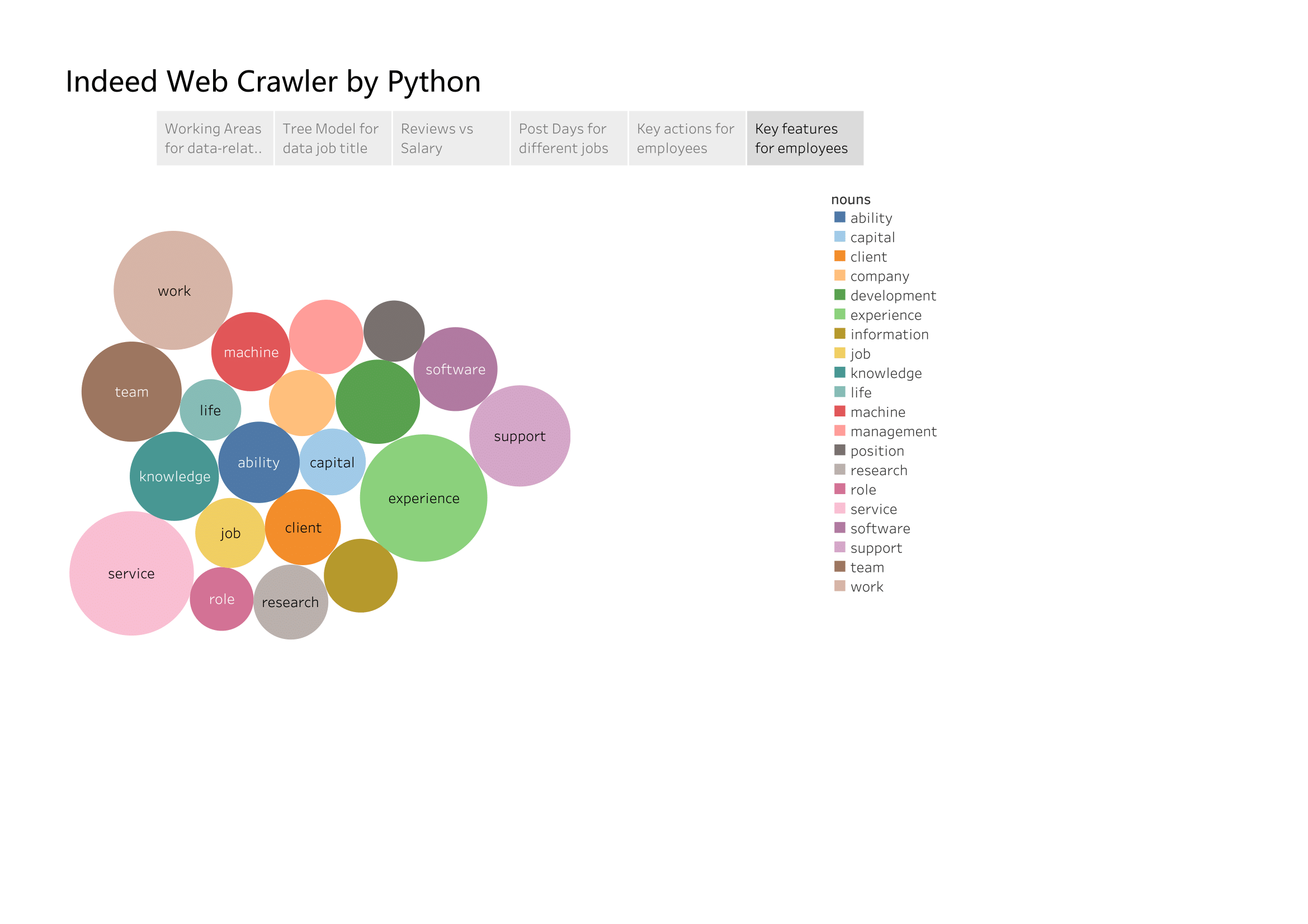
# pick up tags of NN
nouns = [i for i,j in nltk.pos_tag(keywords) if j == 'NN']
print('Total Nouns now: ',len(nouns))
print('-'*40)
print('Unique Nouns now: ',len(set(nouns)))
Total Nouns now: 108818
----------------------------------------
Unique Nouns now: 1912
pd.Series(nouns).value_counts().head(15).plot.barh(title = 'Top 15 Words in job description',colormap = 'summer')
plt.show()
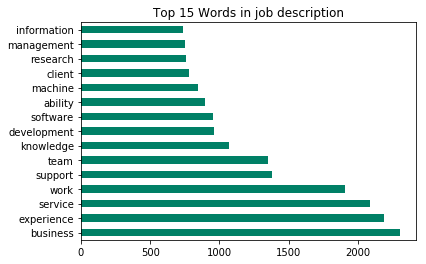
Nouns are more likely to be useful skills or features that employers want.
I find that experience is the most important features employers need (since business is almost useless). Most of companies dont want to hire new-grad since they need many time to train. Others features like support or team mean most of jobs need many staff working together. I think that ‘machine’ is part of ‘machine learning’ since there are also many ‘learning’ in the list. Lastly, ‘client’ means most of companies post on indeed are customer-oriented organization instead of acedemic institution.
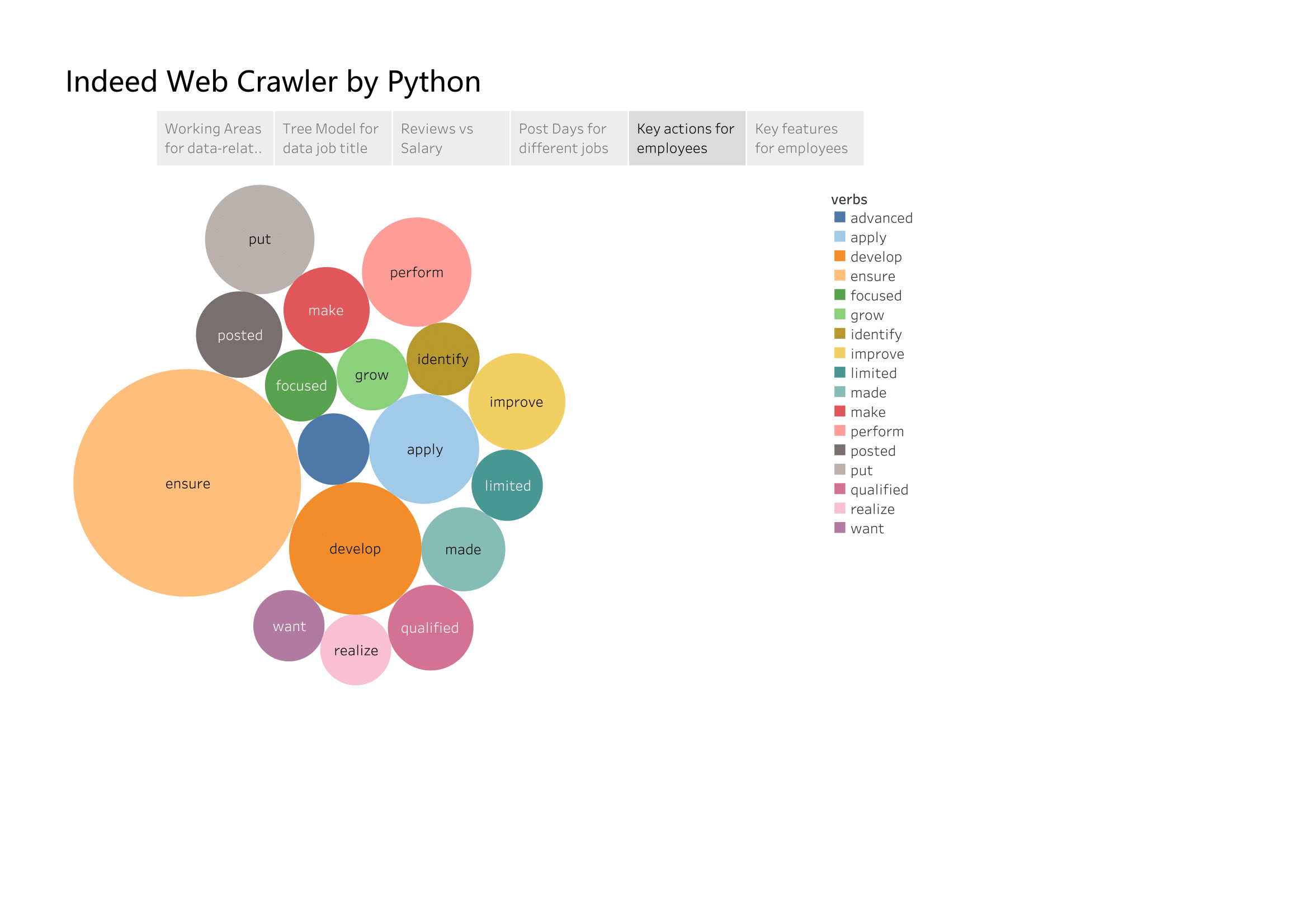
# pick up tags of VB
verbs = [i for i,j in nltk.pos_tag(keywords) if j in ['VB','VBD']]
print('Total Nouns now: ',len(verbs))
print('-'*40)
print('Unique Nouns now: ',len(set(verbs)))
Total Nouns now: 9443
----------------------------------------
Unique Nouns now: 235
pd.Series(verbs).value_counts().head(15).plot.barh(title = 'Top 15 Words in job action',colormap = 'summer')
plt.show()
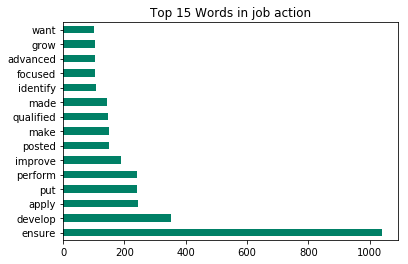
verbs are more likely to be the actions employees need to do.
Verbs can be seperated into some groups : ‘develop / improve / grow’ means increasing the performence or experience of company or clients. ‘qualified / ensure / perform’ means be able to do something. And the count of ‘ensure’ is much more tha others.
# list to csv and make visualization via tableau
pd.DataFrame(nouns,columns = ['nouns']).to_csv('keyword.csv',index = False)
# list to csv and make visualization via tableau
pd.DataFrame(verbs,columns = ['verbs']).to_csv('keyword.csv',index = False)
# list to csv and make visualization via tableau
pd.DataFrame(df).to_csv('indeed.csv',index = False)
Visualization Part with Tableau
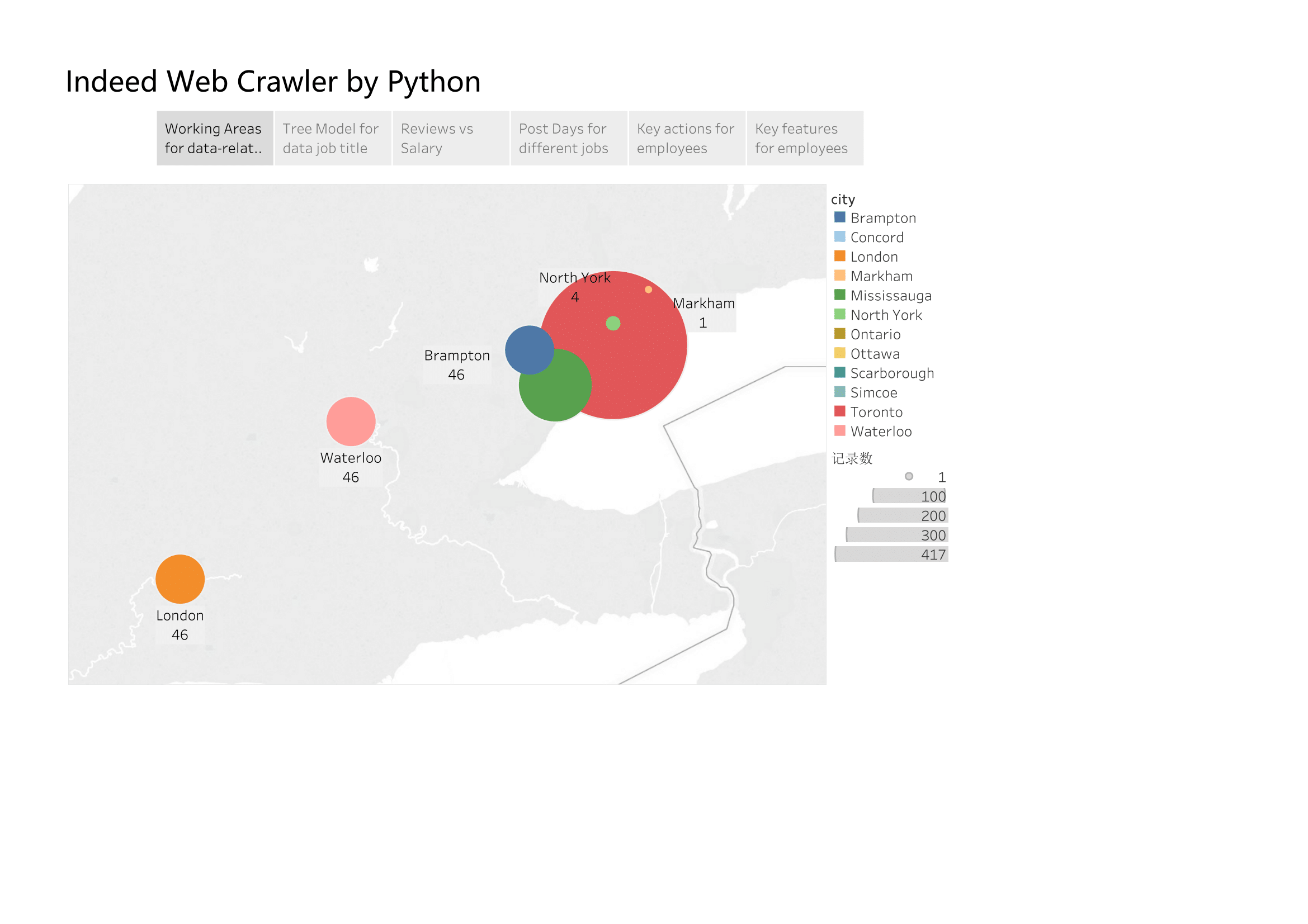
Toronto has more Opportunities than other cities and the main reason is that Toronto is the largest city in Ontario. But for smaller cities there are also some good chance for us.
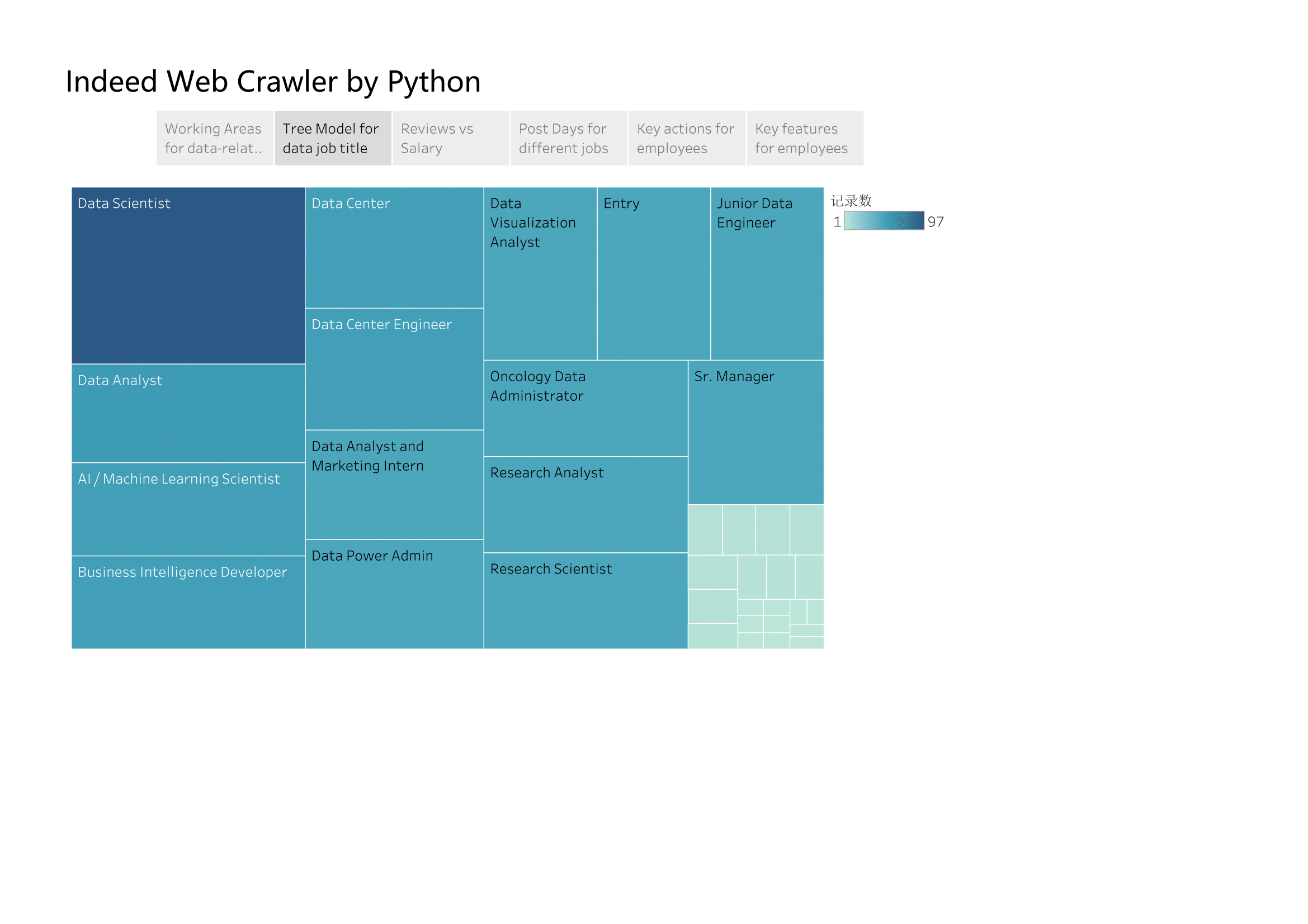
Data Scientist is the most welcomed jobs recently and there are some more data-Scientist-related job titles, such as Machine Learning Scientist and research Scientist. Meanwhile, most of job titles are ‘advanced-level’, which need more that 7 years working experience to apply, such as Sr.manager and data power admin. While there are a few intern jobs posting recently for summer students.
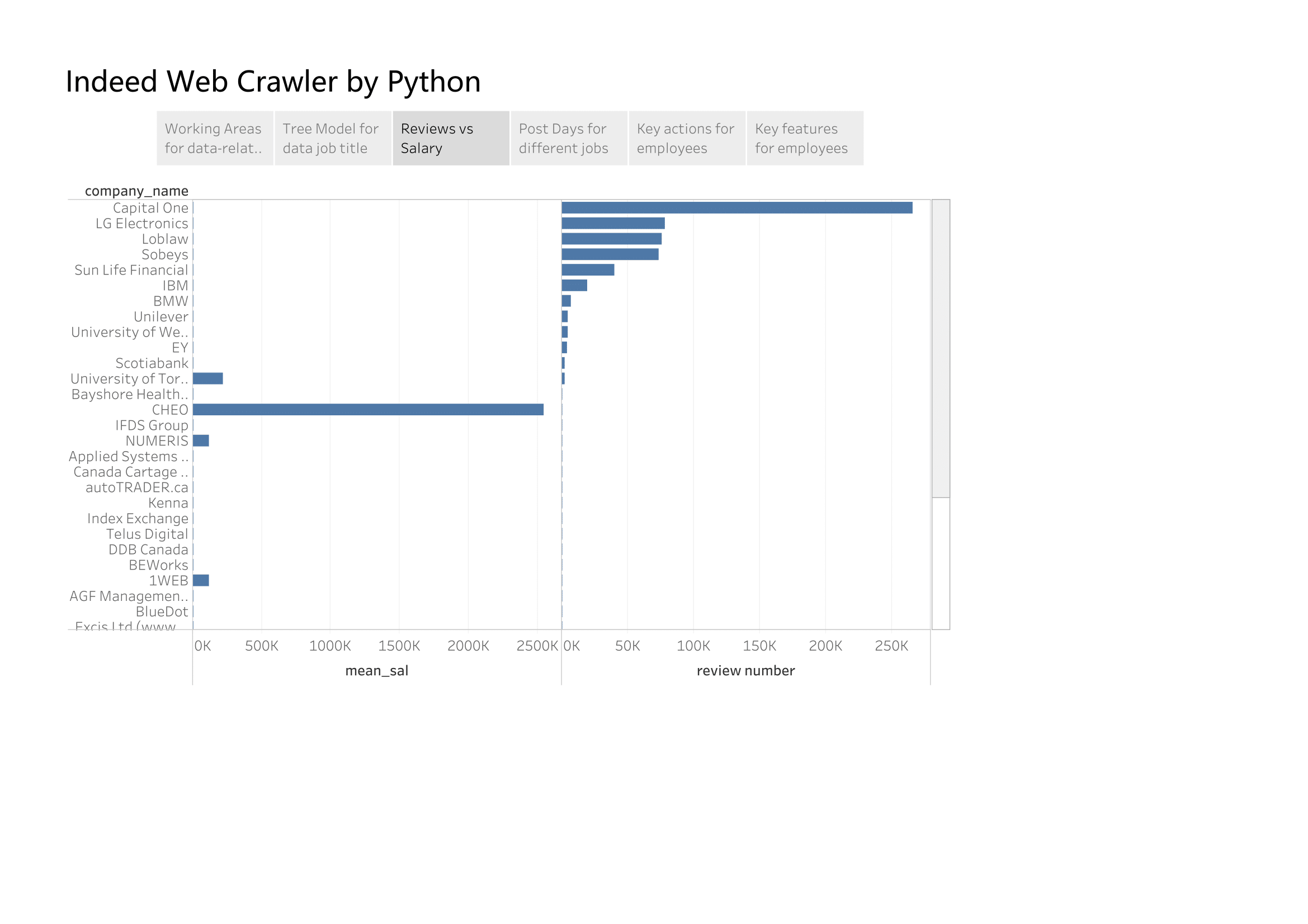
Most of companies who has lots of reviews don’t post the salary information, the companies who posted salary information has less reviews but not zero.
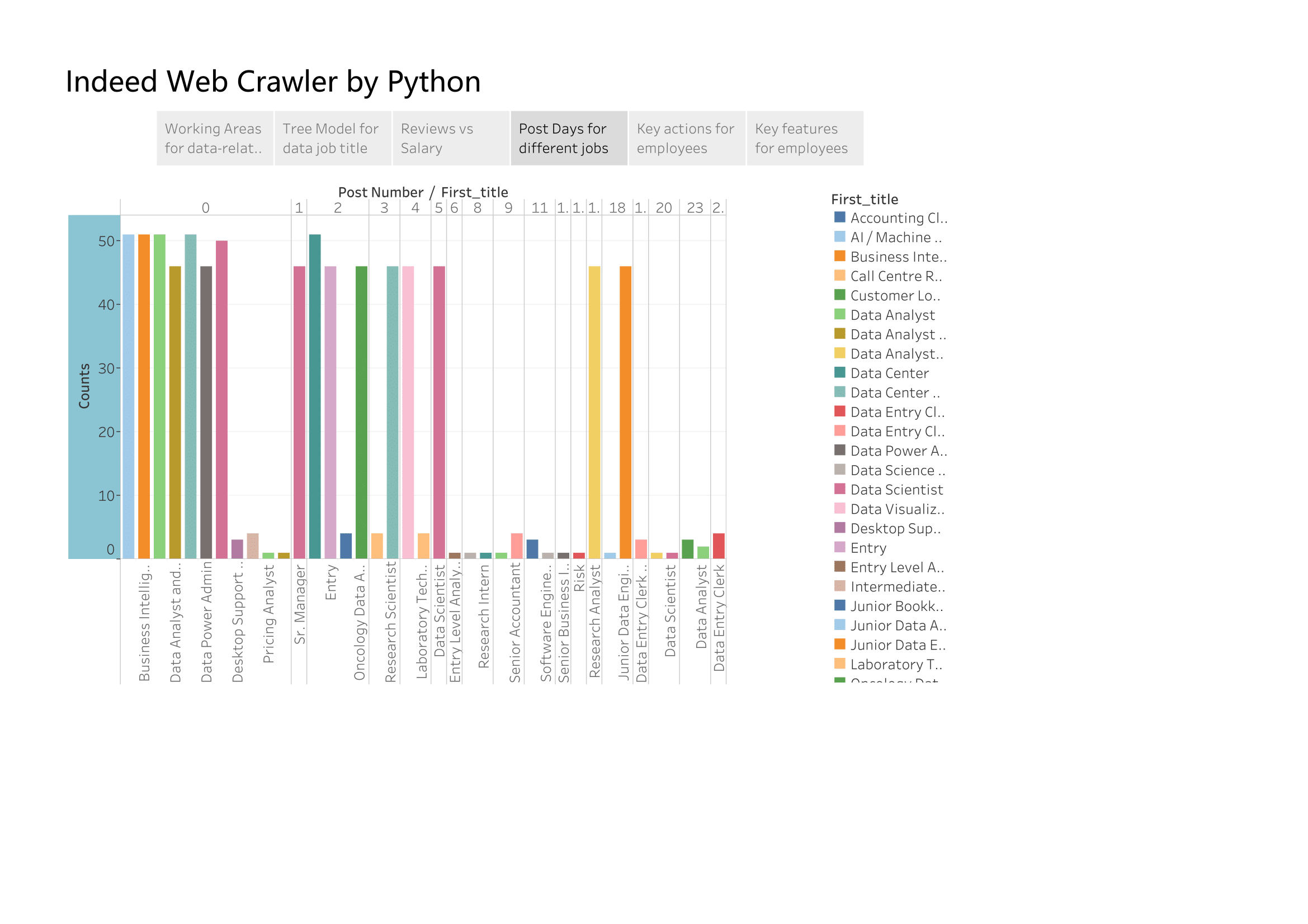
Although for each job, they will list for more than 30 days, we can still find out the trend of posting job title by ‘post days’. Post days equal 0 means this is a new post jobs. For all new post jobs, BI analytics, data power admin and data analytics are more needed than others.