-*- coding: utf-8 -*-
# Created on Sat Feb 17 10:32:35 2018
#Company fuction original code : https://medium.com/@msalmon00/web-scraping-job-postings-from-indeed-96bd588dcb4b
#Find out the data-related jobs in Toronto, ON from Indeed.com
#Do some simple analysis and visualization
#@modify: Haby
# import package
import requests
import bs4
from bs4 import BeautifulSoup
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
Job title and company function code from Medium
https://medium.com/@msalmon00/web-scraping-job-postings-from-indeed-96bd588dcb4b
Demo Code and Function
# Demo URL
# About Url
# 10 jobs list in each page and 4 of them are 'Sponsored' job which is not from searching
url ='https://ca.indeed.com/jobs?q=Data&l=Toronto%2C+ON'
# get the url
page = requests.get(url)
#decode with BeautifulSoup
soup = BeautifulSoup(page.text, 'html.parser')
# job title is under div/a node with data-tn-element/title label
def job_title(soup):
jobs = []
for div in soup.find_all(name='div', attrs={'class':'row'}):
for a in div.find_all(name='a', attrs={'data-tn-element':'jobTitle'}):
jobs.append(a['title'])
return(jobs)
# company title : <span class="company"> in div node
def company(soup):
companies = []
for div in soup.find_all(name='div', attrs={'class':'row'}):
company = div.find_all(name='span', attrs={'class':'company'})
# if can be select by company
if len(company) > 0:
for b in company:
companies.append(b.text.strip())
# else pick up by result-link-source
else:
sec_try = div.find_all(name='span', attrs={'class':'result-link-source'})
for span in sec_try:
companies.append(span.text.strip())
return(companies)
# location
def location(soup):
locations = []
spans = soup.find_all('span', attrs={'class':'location'})
for span in spans:
locations.append(span.text)
return(locations)
# Salary : most of salary doens't exist, fill NA
def salary(soup):
salaries = []
for div in soup.find_all(name='div', attrs={'class':'row'}):
try:
salaries.append(div.find(name = 'span',attrs = {'class','no-wrap'}).text.strip())
except:
salaries.append('Nothing_found')
return(salaries)
# Job Summary
def job_summary(soup):
summaries = []
spans = soup.findAll('span', attrs={'class': 'summary'})
for span in spans:
summaries.append(span.text.strip())
return(summaries)
# Post Day
def post_day(soup):
postday = []
for div in soup.find_all(name = 'div',attrs = {'class','result-link-bar'}):
try :
postday.append(div.find('span',attrs={'class': 'date'}).text)
#spans = soup.findAll('span', attrs={'class': 'date'})
except :
postday.append('New Post')
return(postday)
# Sponsered
def sponsered(soup):
sponsered = []
for div in soup.find_all(name = 'div',attrs = {'class','result-link-bar'}):
try :
sponsered.append(div.find('span',attrs={'class': 'sponsoredGray'}).text)
#spans = soup.findAll('span', attrs={'class': 'date'})
except :
sponsered.append('Non-Sponsered')
return(sponsered)
# reviews
def review(soup):
review = []
for div in soup.find_all(name='div', attrs={'class':'row'}):
try:
review.append(div.find(name = 'span',attrs = {'class','slNoUnderline'}).text.strip())
except:
review.append('0 reviews')
return(review)
# concat all
columns = {'job_title' : job_title(soup), 'company_name' : company(soup),
'location' : location(soup), 'salary' : salary(soup),
'review': review(soup), 'sponsered' :sponsered(soup),
'post day' : post_day(soup),'summary': job_summary(soup),
}
sample_df = pd.DataFrame(columns)
print(sample_df)
company_name \
0 LG Electronics
1 Canada Goose
2 S&P Data LLC
3 Canadian Dealer Lease Services Inc.
4 Viacorp
5 Capital Tech Consulting Inc.
6 Quandl Inc
7 ServiceSimple
8 CanadaStays
9 VICE Canada
10 Visa
11 Rogers Communications
12 Scotiabank
13 DDB Canada
14 LG Electronics
15 Quantumfury Fund
job_title location \
0 AI / Machine Learning Scientist – Toronto AI Lab Toronto, ON
1 IT Analyst Toronto, ON
2 Inbound Call Centre Agent $14.00/hr+Bonus Toronto, ON
3 Junior Reporting Analyst Toronto, ON
4 Data Entry Toronto, ON
5 Data Analyst - Hadoop Toronto, ON
6 Junior Data Engineer (ETL) Toronto, ON
7 Data Analyst and Marketing Intern Toronto, ON
8 Data Analyst Toronto, ON
9 Data Analyst Toronto, ON
10 Data Analyst, Visa Consulting & Analytics Toronto, ON
11 Data Analyst Toronto, ON
12 Data Analyst/Modeler Toronto, ON
13 Junior Data Analyst, Digital Analytics Toronto, ON
14 Director of Artificial Intelligence and Machin... Toronto, ON
15 Artificial Intelligence and Machine Learning D... Toronto, ON
post day review salary sponsered \
0 New Post 1,527 reviews Nothing_found Sponsored
1 New Post 21 reviews Nothing_found Sponsored
2 New Post 338 reviews $14 an hour Sponsored
3 New Post 0 reviews Nothing_found Sponsored
4 11 days ago 0 reviews $600 - $1,400 a week Non-Sponsered
5 5 days ago 0 reviews $70 - $75 an hour Non-Sponsered
6 11 days ago 0 reviews Nothing_found Non-Sponsered
7 30+ days ago 0 reviews Nothing_found Non-Sponsered
8 4 days ago 5 reviews Nothing_found Non-Sponsered
9 2 days ago 0 reviews Nothing_found Non-Sponsered
10 3 days ago 523 reviews Nothing_found Non-Sponsered
11 4 days ago 1,460 reviews Nothing_found Non-Sponsered
12 13 days ago 2,556 reviews Nothing_found Non-Sponsered
13 11 days ago 3 reviews Nothing_found Non-Sponsered
14 New Post 1,527 reviews Nothing_found Sponsored
15 New Post 0 reviews $100,000 - $160,000 a year Sponsored
summary
0 Spark, Hadoop), large scale data analysis, opt...
1 Gather required data from Systems, Vendors, an...
2 Navigate through computerized system and accur...
3 Extracting data sets and cleansing for reporti...
4 Are you a talented and motivated person on the...
5 Work could include moving data around data lak...
6 We are seeking a Junior Data Engineer (ETL) to...
7 Data Analyst and Marketing Intern*. 3 main res...
8 Communicate and evangelize data insights with ...
9 Background in data manipulation and data proce...
10 Extensive experience with SQL for extracting a...
11 You will get exposure to all aspects of the bu...
12 Understand data modeling, metadata knowledge f...
13 Good knowledge of data wrangling, data blendin...
14 Speech, vision, audio, NLP, semantic analysis,...
15 Data modelling, big data and expertise in one ...
Iterating Pages
# Iterate Code
# iterate over pages : there are 10 job list in each page and the new page starts at 10
# ie page 2 :https://ca.indeed.com/jobs?q=Data&l=Toronto,+ON&start=10
url_o = 'https://ca.indeed.com/jobs?q=Data&l=Toronto,+ON&start='
page = [i*10 for i in range(0,41)]
# new dataframe for data
df = pd.DataFrame()#columns = columns)
# loop 40 pages
for i in page :
url = url_o + str(i)
# get the url
page = requests.get(url)
#specifying a desired format of “page” using the html parser - this allows python to read the various components of the page, rather than treating it as one long string.
soup = BeautifulSoup(page.text, 'html.parser')
# concat all
temp = pd.DataFrame([job_title(soup),company(soup),location(soup),
salary(soup),review(soup),sponsered(soup),
post_day(soup),job_summary(soup)])
df = df.append(temp.T,ignore_index = True)
df.columns = ['job_title', 'company_name', 'location', 'salary', 'review',
'sponsered','post day','summary']
print(df.head())
print('-'*40)
print(len(df))
job_title \
0 AI / Machine Learning Scientist – Toronto AI Lab
1 IT Analyst
2 Inbound Call Centre Agent $14.00/hr+Bonus
3 Junior Reporting Analyst
4 Data Entry
company_name location salary \
0 LG Electronics Toronto, ON Nothing_found
1 Canada Goose Toronto, ON Nothing_found
2 S&P Data LLC Toronto, ON $14 an hour
3 Canadian Dealer Lease Services Inc. Toronto, ON Nothing_found
4 Viacorp Toronto, ON $600 - $1,400 a week
review sponsered post day \
0 1,527 reviews Sponsored New Post
1 21 reviews Sponsored New Post
2 338 reviews Sponsored New Post
3 0 reviews Sponsored New Post
4 0 reviews Non-Sponsered 11 days ago
summary
0 Spark, Hadoop), large scale data analysis, opt...
1 Gather required data from Systems, Vendors, an...
2 Navigate through computerized system and accur...
3 Extracting data sets and cleansing for reporti...
4 Are you a talented and motivated person on the...
----------------------------------------
622
Data cleaning
# data cleaning
# Job title
# job title : split first title outside by '-' , ',','?','$'
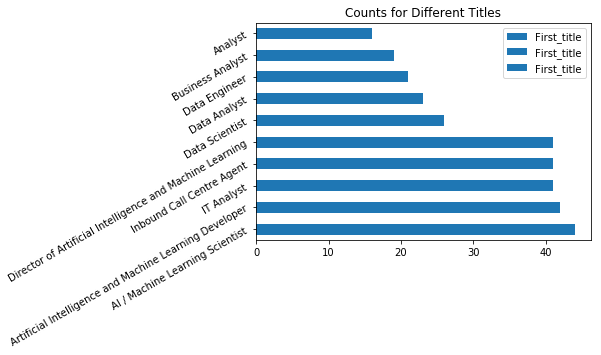
df['First_title'] = df['job_title'].map(lambda x : x.split('–')[0].split(',')[0].split('(')[0].split('$')[0].split('-')[0].strip())
# top 10 job titles
df['First_title'].value_counts()[:10].plot.barh(rot = 30,
title = 'Counts for Different Titles',legend = True)
plt.show()
# salary
# most of salary are 'Nothing_found', replace by 0
df['salary'] = df['salary'].replace('Nothing_found','0')
# make all salary / year
# since most salary exists is a range, get mean value of salary
mean_salary = []
for s in df['salary'] :
if s != '0' :
min_sal = float(s.split()[0].replace('$','').replace(',',''))
if s.split()[1] != '-' :
mean_sal = min_sal
#print(mean_sal)
unit = s.split()[-1]
# print(mean_sal,unit)
if unit == 'week' :
# assume 52 weeks / year
mean_salary.append(mean_sal * 52)
elif unit == 'month' :
mean_salary.append(mean_sal * 12)
elif unit == 'hour':
# assume 40 hours/ week
mean_salary.append(mean_sal * 40*52)
else :
mean_salary.append(mean_sal)
else :
max_sal = float(s.split()[2].replace('$','').replace(',',''))
mean_sal = (min_sal+max_sal)/2
#print(mean_sal)
unit = s.split()[-1]
# print(mean_sal,type(mean_sal),unit)
if unit == 'week' :
# assume 52 weeks / year
mean_salary.append(mean_sal * 52)
#print(df['mean_sal'],'in df')
elif unit == 'month' :
mean_salary.append(mean_sal * 12)
elif unit == 'hour':
# assume 40 hours/ week
mean_salary.append(mean_sal * 40*52)
else :
mean_salary.append(mean_sal)
else :
mean_salary.append(0)
len(mean_salary)
df['mean_sal'] = mean_salary
```python
# number of reviews
df['review number'] = df['review'].map(lambda x : int(x.split()[0].replace(',','')))
# post days
# replace new_post as 0
# other str to int
df['post day'] = df['post day'].map(lambda x : 0 if x == 'New Post' else int(x.split()[0].replace('+','')))
# find keywords in job summary
words = []
for row in df['summary'] :
for word in row.replace(',',' ').replace('.',' ').split() :
word.replace('(',' ').replace(')',' ').strip()
word = word.lower()
words.append(word)
# delete useless elements
dropped = ['and','to','the','of','in','with','a','for','will','is','our','an','data','through','required','business',
'as','from','including','we','are','by','be','for','us','it','.','-','or',
'on','new']
key_words = []
for word in words :
if word not in dropped :
key_words.append(word)
Visualization
#Visualization
# salary visualization
g = sns.kdeplot(df['mean_sal'],shade = True)
g.set_title('Mean Salary for data-related jobs')
plt.show()
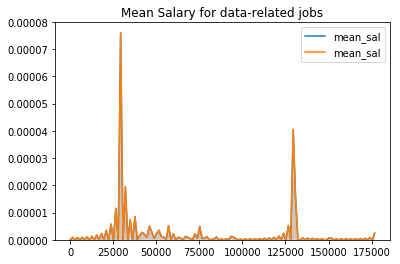
Apperantly there are 3 levels in salary for different level data-workers entry level : salary with 20000 - 40000, medium level : salary with 120000 - 130000, advanced level : salary with more than 175000,
# company name
# graph the top 20 companies who needed the data-related employees recently
df['company_name'].value_counts()[:20].plot.barh(title = 'Top 20 Companies Who Need Data-related Employees')
plt.show()
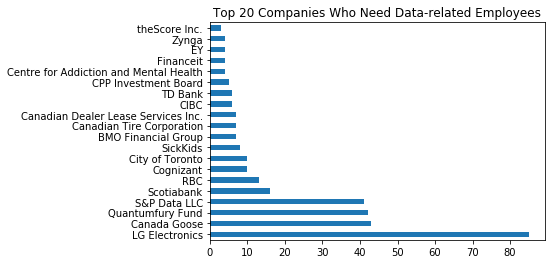
Top 2 is LG Electronics and Canada Goose. For LG company, they have plan to expand the scale of enterprise. I didn’t find some useful information about CG, but I guess they will produce more in winter weather ??
# reviews visualization
# plot top 10 companies with most reviews
df[['review number','company_name']].groupby('company_name').mean().sort_values(by = ['review number'],
ascending = False).head(10).plot.barh(title = 'Top 10 companies with most reviews')
plt.show()
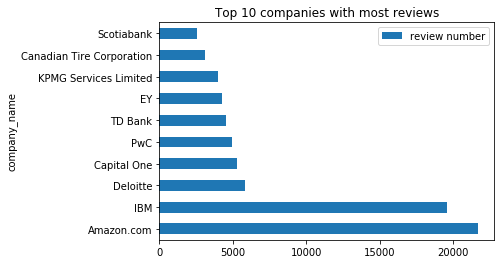
Most of top 10 commanies are so-called ‘big-company’, which can provide the better working environment, benefit and salary. Financial and IT related companies have more reviews than other companies.
# list the top 20 important words in data related job posts
pd.Series(key_words).value_counts()[:20].plot.barh(rot = 30,
title = 'Top 20 Keywords for data-related job',legend = True)
plt.show()
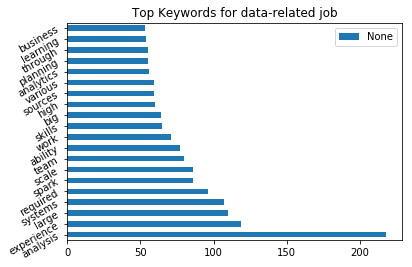
# list the top 20-40 important words in data related job posts
pd.Series(key_words).value_counts()[20:40].plot.barh(rot = 30,
title = 'Top 40 Keywords for data-related job',legend = True)
plt.show()

Top 20 keywords are more likely to be general features for all employees, such as analysis, experience,team,learning while top 20- 40 words are more likely to be professional skills, such as optimization, databases, management,programming. To me, it seems that employers are more care about what kind of person you are or can you work in a team environment rather than what kind of skills you have. This is totally new for me.
# sponsered
# just interested in whether sponsered company is different
sns.countplot(df['sponsered'])
#sns.countplot(df['mean_sal'])
plt.show()
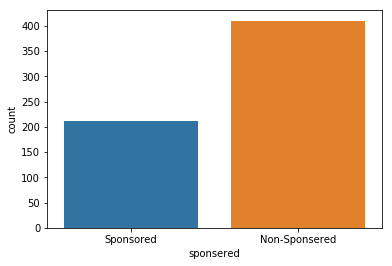
# pair plot with post day /mean salary / reviews number hue by sponsered
sns.pairplot(df,hue = 'sponsered')
plt.show()
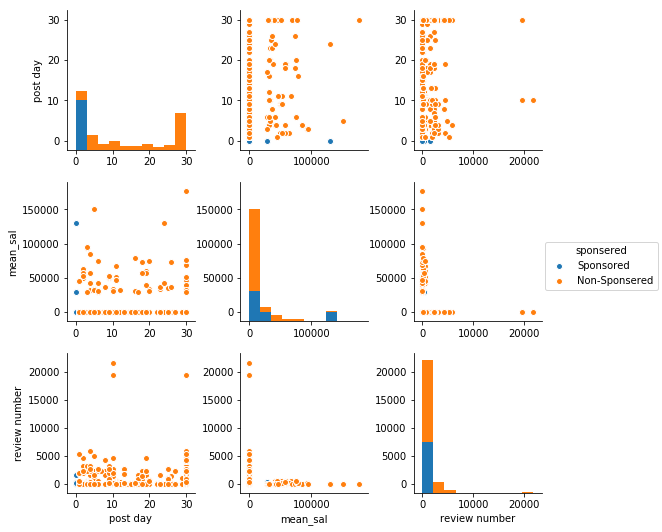
All sponsered posts are new post(post day = 0), which means if you pay, your post will stand on the top/ bottom of first page and don’t need to be worried about poshing down. Most of companies who publish the sponsered post seems to have less reviews, that means either these companies are new companies or these are small-size companies who don’t need so many employees. Although just few of posts offer the salary, for the posts who offer salary information, sponsered posts are majority. Maybe small company size and less reviews means these posts need salary as a highlight for employees.